
The ChemDataExtractor Toolkit
Overview
The ChemDataExtractor toolkit (CDE) is a complete natural language processing pipeline, designed to automatically extract chemical properties from scientific documents (journal articles, patents etc.). This allows the user to analyse thousands of documents and create large databases of material properties. These data can then be used to for data-driven materials discovery. Cool right?
I have worked on CDE for the past 4 years as part of my MPhil and PhD, developing the toolkit for use on magnetic materials.
Related Work
The original toolkit was developed by Matt Swain in the Cambridge Molecular Engineering group. The original publication is here and the corresponding web interface is here.
A number of papers have since been published demonstrating and extending the capabilities of CDE:
A database of battery materials auto-generated using ChemDataExtractor
Comparative dataset of experimental and computational attributes of UV/vis absorption spectra
ImageDataExtractor: A Tool to extract and quantify data from microscopy images
Dye‐Sensitized Solar Cells: Design‐to‐Device Approach Affords Panchromatic Co‐Sensitized Solar Cells
In summary, the toolkit is very general, and can therefore be applied in any domain.
How it works
This figure gives an overview of the CDE pipeline.
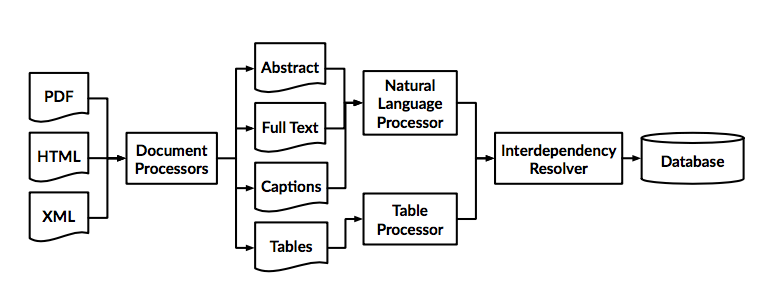
The Document Processors break down the input documents into their constituent elements (text, tables, figures etc), and these are passed through separate relationship extraction pipelines for identifying chemical relationships.
The Interdependency Resolver links the relationships together to resolve dependencies across different document elements. E.g. linking chemical labels to the correct chemical formula.
The result is a set of mutually consistent chemical records that can be placed into a database.
This is probably best explained through an example.
An Example - Extracting Melting Points
Let’s say we have the following (contrived) example document*:
On the Melting Point of Water Abstract In this work we analyse the melting point of water. Specifically, the temperature at which solid water (also known as ice), undergoes a transition to liquid form.
Results
This section describes the results of our experiments on Sample 1 ($H_2O$). It was found that Sample 1 underwent the solid-liquid phase transition under heating at 273.15 K.
* Note that this above work is highly propietary research and should not be stolen under any circumstances…
Firstly, CDE breaks this document down into sections:
- Title
- Heading
- Paragraph
- Heading
- Paragraph
The sentences are further tokenized down to word tokens.
The key information is contained in a few sentences:
“This sections describes the results of our experiments on Sample 1 ($H_2O$)”
This identifies two entities, a chemical formula and a corresponding label. This effectively creates the link that Sample 1 == $H_2O$.
“…Sample 1 underwent the solid-liquid phase transition … 273.15 K”
This finds a melting point relationship of (melting point, 273.15, Kelvin, Sample 1)
Finally the interdependency resolvers link the two records to give a final record:
Compound: $H_2O$ Labels: Sample 1 Value: 273.15 Unit: Kelvin
and voila, we have a complete record!
Further Reading
I have written some blog posts on how to use CDE in more detail. You can also clone the repository and have a play with it yourself!
Happy extracting.